

Building a Serverless REST API with Fauna, AWS, and TypeScript
This blog post teaches you how to build robust, scalable, type-safe serverless REST APIs using AWS Lambda functions, Fauna database, and TypeScript.
Prerequisites:
- Node.js (20 or current LTS)
- AWS CLI v2
- Serverless Framework
- AWS account
- Fauna account
By the end of this blog post, you will be able to
- Perform CRUD (Create, Read, Update, Delete) operations from Lambda functions with Fauna as the data layer
- Manage Fauna database with the Serverless Framework
- Manage and deploy your application with the Serverless Framework.
Before we continue it is a good idea to understand Fauna and the Serverless Framework, and why these two together make a good fit. Fauna is a serverless, globally distributed database that offers flexible and scalable data storage. It enables developers to build applications without worrying about managing servers or infrastructure. On the other hand, the Serverless Framework simplifies the deployment and management of serverless applications by providing a set of tools and abstractions. It streamlines the process of building and deploying functions as well as managing cloud resources. Combining Fauna with the Serverless Framework presents a powerful synergy. Fauna's serverless architecture seamlessly aligns with the Serverless Framework's approach -- reducing complexities, enabling faster development, and ensuring scalability. In a nutshell, this combo lets you concentrate on creating a killer app without worrying about the nitty-gritty of server management or database scaling.
Create a new project
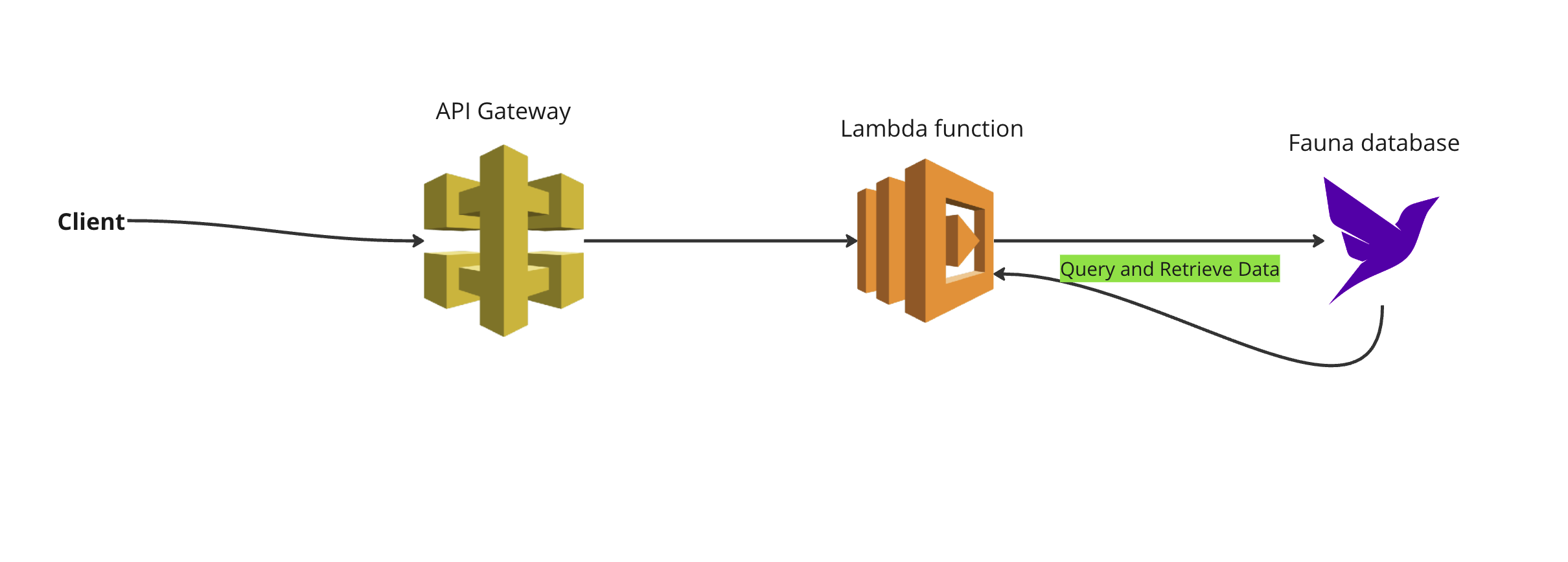
The following diagram demonstrates the architecture of the application we are going to build. In this application the API Gateway serves as the entry point, routing requests to the corresponding Lambda functions for Create, Read, Update, and Delete operations on inventory items. The Lambda functions store and query data from the Fauna database.
Create a new Serverless project by running the following command:
$ serverless create --template aws-nodejs-typescriptNotice that we use the aws-nodejs typescript template, which scaffolds a lot of code for you. This way, you don't have to write everything from scratch.
Next, add serverless-fauna and serverless-dotenv-plugin as dependencies on your project by running the following command in your terminal:
$ npm i severless-fauna serverless-dotenv-plugin --saveConfigure Fauna resources
Open the project directory in your favorite code editor. Open the serverless.yml file and add the following code:
service: aws-serverless-api-v2
frameworkVersion: "3"
# Specify donenv
useDotenv: true
# Specify provider
provider:
name: aws
runtime: nodejs20.x
# specify providers
plugins:
- serverless-plugin-typescript
- serverless-offline
# Fauna configuration
fauna:
version: 10
client:
secret: ${env:FAUNA_SECRET}
collections:
Inventory:
name: InventoryYou define all the Fauna resources you want to create in the YML file. For instance, in the previous code block, you create a new “database” collection called ‘Inventory’.
Next, head over to Fauna and create a new server key for your database. Create a new
.env file at the root of your project. Add the Fauna key and domain as environment variables.FAUNA_ROOT_KEY='fnA.............'💡 Pro tip: You can use AWS Secret Manager to store your Fauna key. This is best practice for production applications. To do so add the AWS Secrets Manager resource definition into your serverless.yml file. Add the following lines of code to your serverless.yml file:
# serverless.yml
# … rest of the code above
resources:
# AWS Secrets Manager resource definition
Resources:
FaunaSecret:
Type: AWS::SecretsManager::Secret
Properties:
Name: /aws/reference/secretsmanager/fauna_secret
Description: "Fauna DB secret for the application"
# You can set the initial value of the secret here or leave it to configure manually in AWS Console.
SecretString: '{"FAUNA_SECRET": "your-initial-secret-value"}'Configure AWS Lambda
Next, add the Lambda configuration to your YML file. Add the following code snippet to your YML file:
# ... rest of the serverless.yml file
provider:
name: aws
runtime: nodejs18.x
# Lambda configuration
functions:
create:
handler: handler.create
events:
- http:
path: /
method: post
readAll:
handler: handler.read
events:
- http:
path: /
method: get
readOne:
handler: handler.read
events:
- http:
path: /{id}
method: get
update:
handler: handler.update
events:
- http:
path: /{id}
method: put
delete:
handler: handler.deleteItem
events:
- http:
path: /{id}
method: delete
# ...Rest of the codeIn the previous code snippet, you create a Lambda function to handle Create, Read and Update and Delete scenarios.
Write Lambda “function” code
Next, write the code for your Lambda functions. You need the Fauna sdk to connect to Fauna from your Lambda functions. Install the Fauna package in your project by running the following command:
$ npm i fauna --saveOpen the handler.ts file and add the following code snippet. In the following code snippet, you initialize the Fauna sdk. Then you create functions to query and insert data to Fauna.
import { APIGatewayProxyHandler } from "aws-lambda";
import { Client, QuerySuccess, fql } from 'fauna';
type InventoryItem = {
name: string;
price: number;
quantity: number;
};
const client = new Client({ secret: process.env.FAUNA_SECRET });
export const create: APIGatewayProxyHandler = async (event) => {
try {
if (!event.body) {
return {
statusCode: 400,
body: JSON.stringify({ error: 'Invalid request body' }),
};
}
const data = JSON.parse(event.body) as InventoryItem;
if (!data) {
return {
statusCode: 400,
body: JSON.stringify({ error: 'Parsed data is invalid' }),
};
}
const response: QuerySuccess<InventoryItem> = await client.query(
fql`Inventory.create(${data})`
);
return {
statusCode: 200,
body: JSON.stringify(response),
};
} catch (error) {
return {
statusCode: 400,
body: JSON.stringify(error),
};
}
};
export const deleteItem: APIGatewayProxyHandler = async (event) => {
if (!event.pathParameters || !event.pathParameters.id) {
return {
statusCode: 400,
body: JSON.stringify({ error: 'ID is required' }),
};
}
console.log('Path Parameters:', event.pathParameters);
const id = String(event.pathParameters.id);
try {
const response: QuerySuccess<InventoryItem> = await client.query(fql`
let toDelete = Inventory.byId(${id})
toDelete!.delete()
`);
return {
statusCode: 200,
body: JSON.stringify(response),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: error.message }),
};
}
};
export const read: APIGatewayProxyHandler = async (event) => {
try {
if (event.pathParameters && event.pathParameters.id) {
console.log('Path Parameters:', event.pathParameters.id);
const id = String(event.pathParameters.id);
const response: QuerySuccess<InventoryItem> = await client.query(
fql`Inventory.byId(${id})`
);
return {
statusCode: 200,
body: JSON.stringify(response),
};
} else {
const response = await client.query(
fql`Inventory.all()`
);
return {
statusCode: 200,
body: JSON.stringify(response),
};
}
} catch (error) {
return {
statusCode: 400,
body: JSON.stringify(error),
};
}
};
export const update: APIGatewayProxyHandler = async (event) => {
try {
if (!event.pathParameters || !event.pathParameters.id) {
return {
statusCode: 400,
body: JSON.stringify({ error: 'ID must be provided.' }),
};
}
if (!event.body) {
return {
statusCode: 400,
body: JSON.stringify({ error: 'Invalid request body' }),
};
}
console.log('Path Parameters:', event.pathParameters.id);
const id = event.pathParameters.id;
const data = JSON.parse(event.body);
const response: QuerySuccess<InventoryItem> = await client.query(fql`
let itemToUpdate = Inventory.byId(${id});
itemToUpdate!.update(${data})`
);
return {
statusCode: 200,
body: JSON.stringify(response),
};
} catch (error) {
return {
statusCode: 400,
body: JSON.stringify(error),
};
}
};In the code above, the core functionality is divided into several functions. The create function adds new items to the inventory, involving validation and parsing of the request body. The ‘deleteItem’ function is employed for deletion purposes, which verifies the presence of an item ID and instructs Fauna to remove the specified item. The ‘read’ function caters to information retrieval, capable of fetching either a specific item or a complete list from the inventory, depending on the provided parameters. The ‘update’ function is designed for modifying existing items, requiring both the item ID and new data for successful execution.
Deploy your stack
Deploy your stack by running the following command.
$ sls deployTo clean up (delete all the resources in AWS and Fauna) you can run the following command.
$ sls destroyCheck out the Fauna official documentation page to learn more about Fauna. Want to learn more about the Serverless Framework? Check out their official documentation page. You can find the complete code in the following git repository.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.