

NEW

How Fauna and Cloudflare Make Serverless Development Faster & More Scalable
In a world where we demand speed, flexibility, and seamless scalability, serverless architecture has emerged as a new gold standard. For many developers, achieving a truly serverless experience — where every element of scaling, replication, and data consistency is managed without additional infrastructure headaches — can still seem elusive. Fauna, in partnership with Cloudflare, has made 'True Serverless' possible. In this post, I cover how Fauna and Cloudflare Workers empower you to build, deploy, and scale globally without compromising on true serverless simplicity, easy global scaling, and the ability to evolve applications without downtime.
But don’t just take my word for it; ask Cameron Bell, Head of Software, Systems, & Data at Connexin, who shared, “Fauna is a true serverless database. This is very important for applications like ours where much of the infrastructure – like Cloudflare Workers – is connectionless and requires solutions that can meet the demands of real-time, operational data. The serverless attributes of Cloudflare and Fauna mean we can genuinely do more, faster.”
True serverless: No provisioning, replication, or clustering
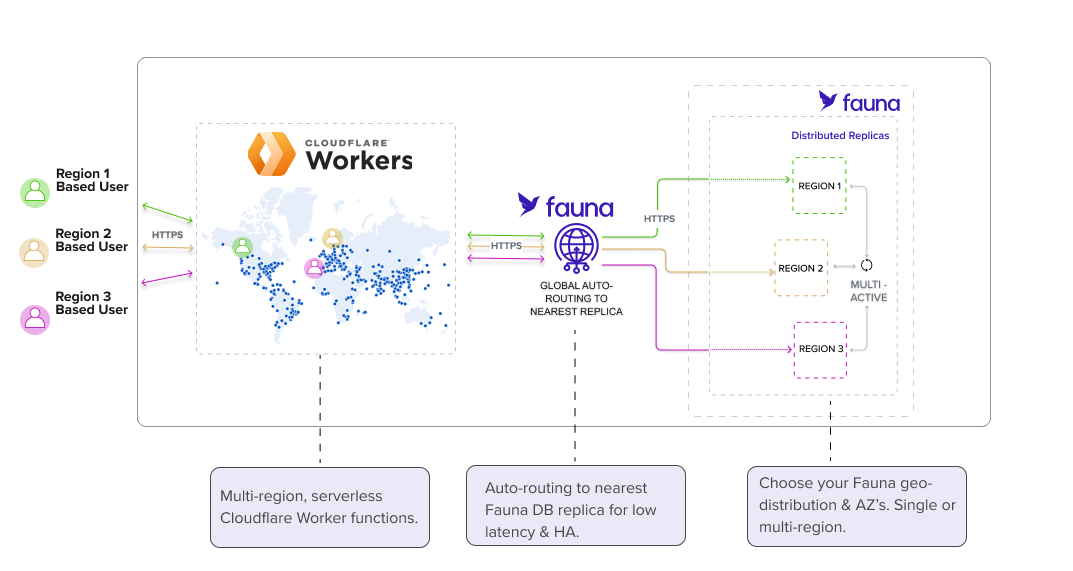
One of the core tenets of a serverless architecture is zero operational overhead. Fauna and Cloudflare’s integration lets you forget about provisioning servers, configuring clusters, or handling complex replication. Fauna’s document-relational model natively supports data consistency across multiple regions, and Cloudflare’s global edge network seamlessly distributes workloads. This combination allows your application to scale automatically based on usage, giving you all the benefits of global performance without needing to manage infrastructure. In other words, the architecture scales to your application’s needs—without requiring you to manage the backend setup.
Ultra-fast multi-region and edge workloads with strong consistency
When it comes to applications that serve a global audience, speed and data consistency are essential. Traditional databases struggle to provide both, often sacrificing one for the other. Fauna’s distributed transaction engine provides data consistency across all regions in a region group without the lag of traditional replication methods. In addition, your data is always strongly consistent across those regions. Paired with Cloudflare Workers and their edge network, your application can support ultra-low-latency requests around the globe, and your app always connects to the closest Fauna replica. This setup not only ensures fast responses but also guarantees consistency, letting users access the most up-to-date data with low latency, no matter where they’re located.
Rapid time-to-market with simplified deployments
With Fauna’s native integration with Cloudflare Workers, app development is accelerated by eliminating development and infrastructure management tasks. Fauna’s database enables instant global access through its API, which communicates over HTTPS, so your app can connect securely using Fauna’s client libraries or make direct HTTPS requests. This native integration means Cloudflare Workers can interact directly with Fauna without needing traditional database connection pools, middleware, ORMs, or complex backend setups. This makes data handling within your Cloudflare Workers faster and more efficient.
By reducing development steps from start to deployment, Fauna and Cloudflare enable you to skip backend infrastructure management, allowing you to focus entirely on building features. The streamlined connection keeps your code lean and responsive, helping you to bring products to market faster, while delivering a scalable, high-performance experience to your users.
Keep applications lightweight, performant, and easy to maintain
Complex app logic often makes apps slower to execute, tricky to test, and difficult to manage over time. Fauna’s powerful query language, FQL, enables you to build complex data relationships without writing extensive application code. With Fauna’s UDFs (user-defined functions), you can embed FQL code to run in the database. This streamlined data management means that, within Cloudflare Workers, your logic remains lean and focused. Fauna handles the heavy lifting of relational data and consistency, enabling your application to remain lightweight and performant—even as it scales to meet global demand. In addition, testing new application code is easier and more repeatable as the heavy lifting can be done in UDFs.
Fauna also has native zero-downtime migrations for database schema changes, which allows you to evolve your data model without taking your application offline or disrupting the user experience. As your application grows and requires changes to its data structure, you can roll out updates smoothly, maintaining high availability and minimizing the need for extensive backend reconfiguration. This enables you and your team to iterate quickly, delivering new features and products to market faster but in a controlled fashion.
Conclusion
By combining Fauna’s flexible, distributed, and strongly consistent database with Cloudflare Worker’s edge-first architecture, you unlock a fully managed serverless stack that lets you focus on building your application, not on managing infrastructure. This partnership enables you to scale without limits, ensures ultra-fast, globally consistent data, and keeps your codebase lean — all key to getting your products to market faster and your customers happy.
If you’re ready to embrace a true serverless architecture, sign up for a free Fauna account and check out the Fauna & Cloudflare workshop to see just how easy it is to get started.
As always, feel free to contact us if you'd like to set up a demo or have any questions.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, and serverless databases, Fauna is hiring
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.