

NEW

Scaling Reads and Writes without Managing Clusters
When it comes to scaling your database for higher read and write demands, the traditional approach often involves adding more servers, configuring clusters, and diving into the complexity of read replicas and sharding. This not only slows down your development cycle but also pulls valuable engineering resources away from building core features. In this post, we’ll explore how Fauna takes a completely different approach—one that eliminates cluster management entirely and scales seamlessly on your behalf.
The Problem with Traditional Scaling
In a conventional database setup, you typically have to figure out the right combination of servers or instances to handle the traffic. If your workload is read-heavy, you add more read replicas.

If it’s write-heavy, you will likely shard your data and add new partitions.

Sometimes you end up doing both, all while juggling cluster configurations and trying to keep your data consistent.

This complexity adds operational overhead, increases costs, and can create bottlenecks as you grow. Even “serverless” or “managed” database options often require you to specify the number of replicas or nodes you need. These tasks sap valuable engineering time and can slow your ability to release new features.
Eliminating Scaling Overhead with Fauna
Fauna offers a completely different model. You simply choose the region group you want to deploy your database in, and Fauna handles the rest. Your application connects via a single endpoint, and Fauna automatically manages consistency, scaling, and replication across three multi-active replicas within that region group.

Creating a Database in Fauna

Getting started with Fauna is straightforward. In the Fauna dashboard, click to create a new database, provide a name, choose your region group (e.g., Europe, US, etc.), and optionally enable features like demo data or backups. After hitting Create, your new database is ready, and automatically distributed across three data centers for high availability and strong consistency.
Once created, you’ll see your demo data (if selected), including collections such as customer. In a relational world, these collections are analogous to tables.
Querying Data
Fauna’s dashboard includes a built-in Query Editor. Think of this as a command-line console where you can test and execute the Fauna Query Language (FQL). For example, to fetch all documents in the customer collection, you might run:
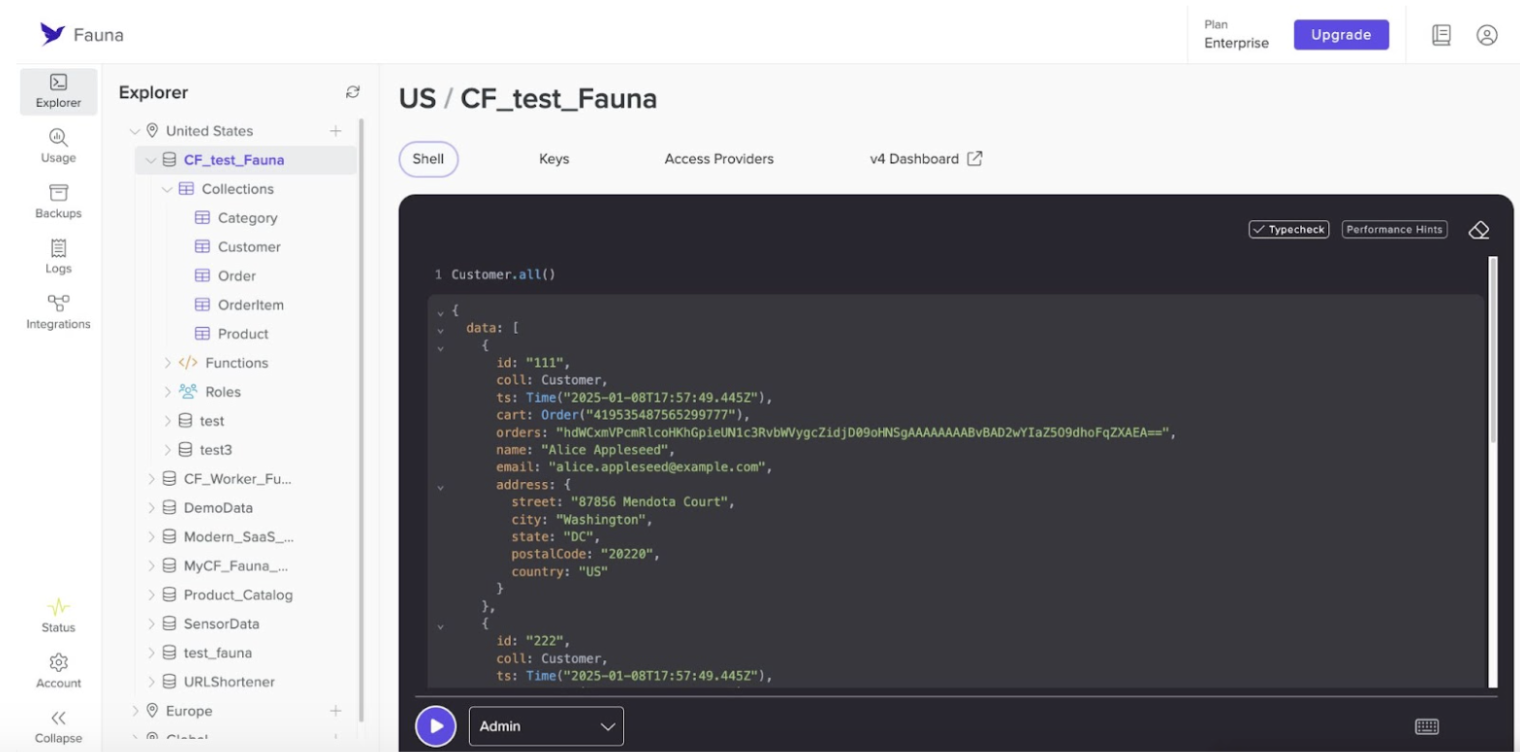

This is similar to running a 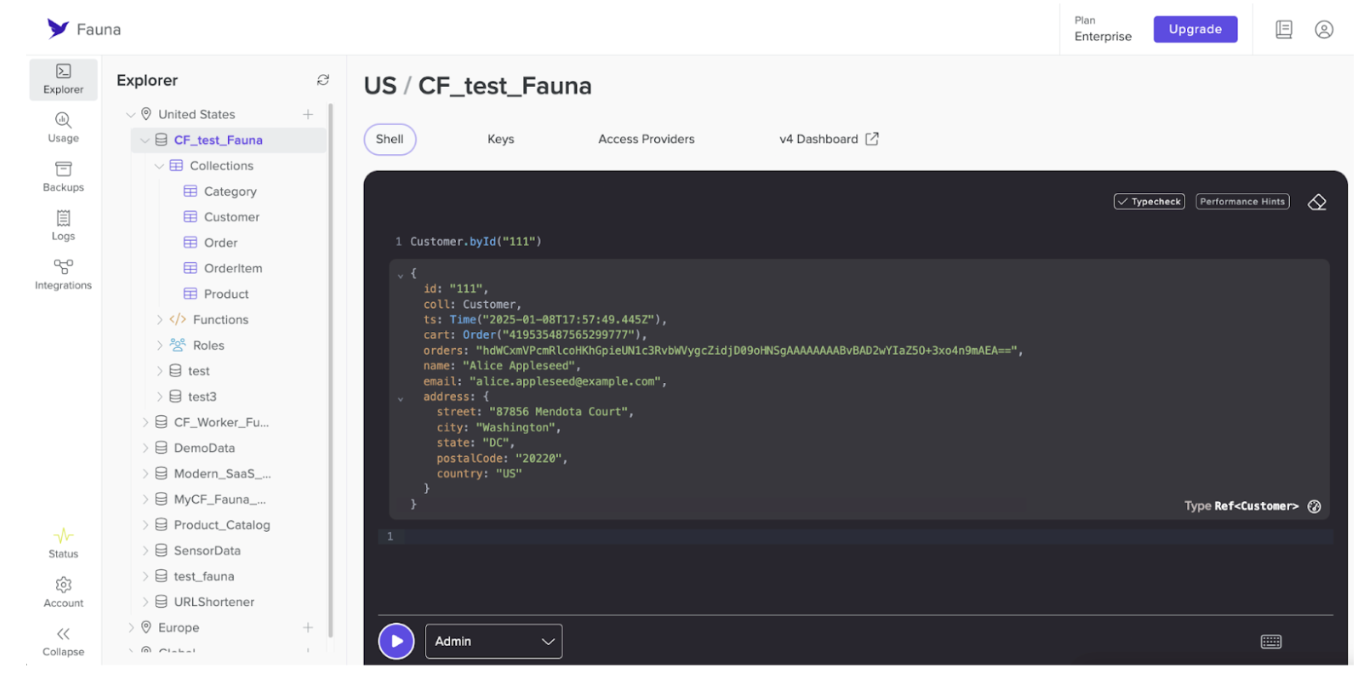
SELECT * FROM customer in a SQL-based database, but with Fauna’s modern, document-relational approach. If you want a specific record, you can reference its ID:

Connecting Through Code
Beyond the dashboard, Fauna also offers easy integration in code. Here’s a quick look at a TypeScript example designed for Cloudflare Workers (check out the Fauna + Cloudflare Workers quick-start here):
Set Up the Client Connection
const client = new Client({ secret: env.FAUNA_SECRET });- This snippet creates a Fauna client, pulling the secret (API key) from an environment variable or using Cloudflare Workers’ native Fauna integration.
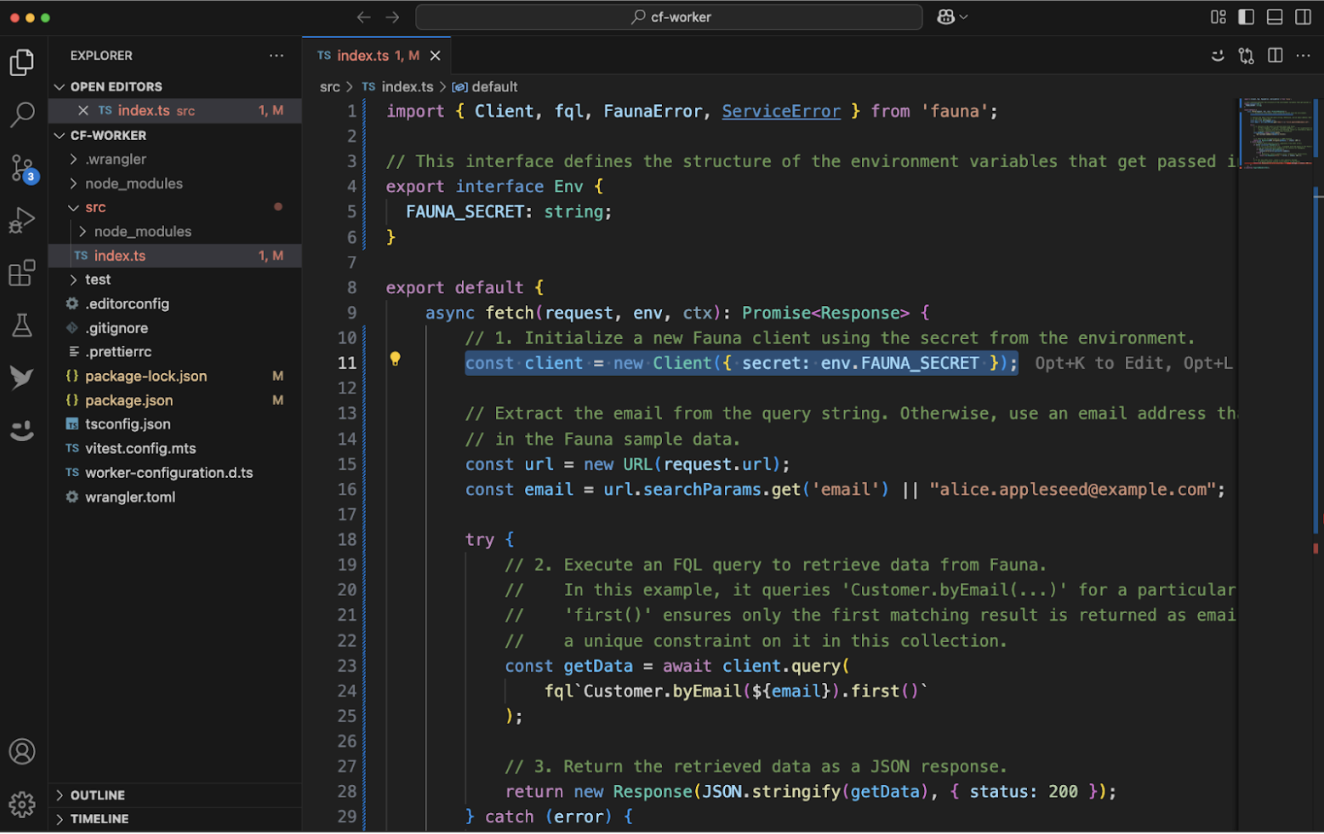

Make Queries
const email = url.searchParams.get('email');
const getData = await client.query(
fql`Customer.byEmail(${email}).first()`
);
- This code calls a Fauna index name byEmail that retrieves a customer by email, returning a single matching document.
Everything about Fauna aims to keep your development cycle smooth—no cluster management, no extra read replicas, and no hidden scaling complexities. As your application grows, Fauna seamlessly ramps up resources to handle the workload.
A Truly Serverless Experience

In your database settings, you’ll find minimal configuration options—no advanced cluster or replication menus. That’s intentional. Fauna automatically handles regional replication and consistent writes, all while you focus on building your application. You simply indicate where you’d like your data to live, and Fauna ensures it remains available, strongly consistent, and protected. No knobs and switches, no guesswork. Fauna’s truly serverless architecture handles everything regarding scaling for you.
Conclusion
Scaling databases has traditionally been a headache—balancing read replicas, sharding data, and configuring clusters. Fauna removes these burdens by offering a serverless, globally distributed environment where you pay only for the queries you run. Whether running a small side project or managing enterprise-level traffic, Fauna seamlessly adapts to your needs with minimal operational overhead.
So, if you’re tired of managing database clusters and want to focus on delivering features instead, give Fauna a try. Create a database, write some data, and see how quickly you can scale—without touching a cluster configuration. Check out the accompanying video to see this live, and be sure to sign-up for a free account to get started.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, and serverless databases, Fauna is hiring
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.