

Building AI applications with OpenAI, Pinecone, Langchain and Fauna
In this article, we'll explore how a general-purpose database (i.e., Fauna) combined with a vector database can be harnessed to provide GPT agents with long-term memory capabilities. This integration will improve the quality and relevance of the GPT agent's responses and open the door to more advanced and personalized interactions.
For further discussion on how Fauna is used as system of record in a generative AI stack and why Logoi is using Fauna as a knowledge graph and metadata store for their gen AI app, please check out Fauna: A modern system of record for your generative AI application.
Let's build a sample application to demonstrate these capabilities. Imagine we are making a personalized AI-powered travel agent for the travel industry. Let's call our app WanderWise. WanderWise simplifies the process of discovering and planning your perfect getaway.
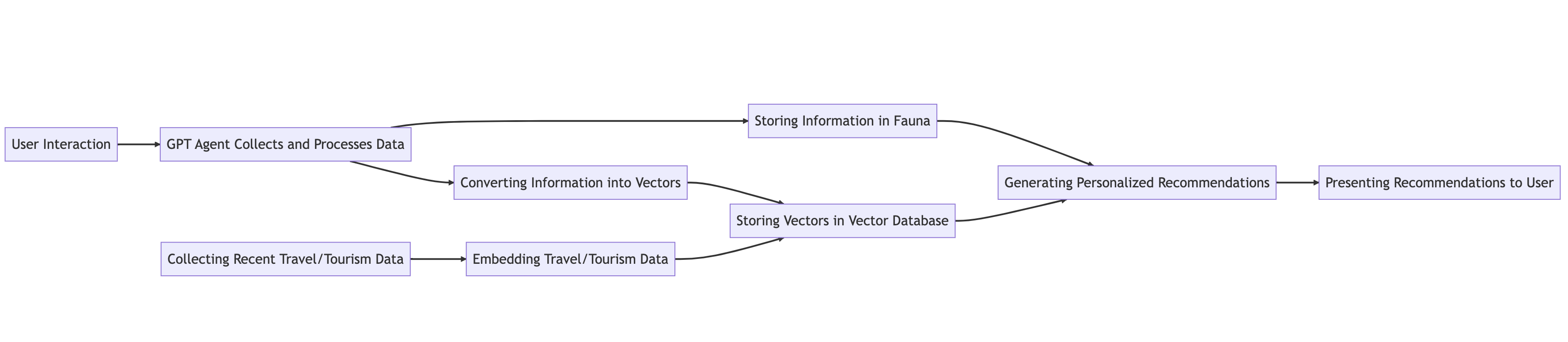
Here's how the application works:
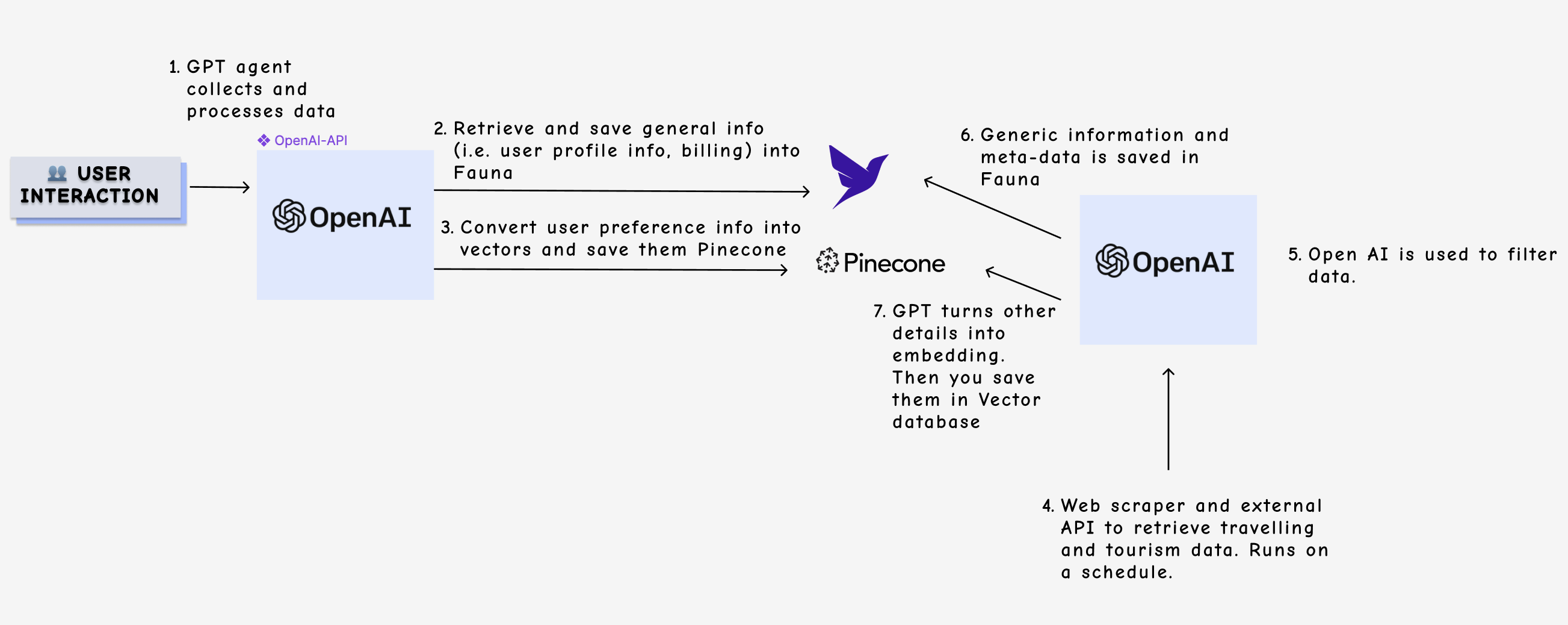
- GPT agent collects and processes data: A user interacts with a GPT agent to plan their ideal vacation. The agent asks about their preferences, such as preferred activities, budget, and past travel experiences. As the conversation progresses, the agent collects and processes this information to create a user profile.
- Storing information in a general-purpose database: The GPT agent stores the user's textual information, such as their name, preferences, and previous travel experiences, in a general-purpose database (in this case, Fauna). This database allows the agent to store structured data and perform complex queries to retrieve relevant information later.
- Converting information into vectors and storing it in a vector database: The GPT agent converts the user's preferences and past experiences into a high-dimensional vector representation using techniques like word embeddings or sentence embeddings. These vectors are then stored in a vector database, which is optimized for efficient similarity search and vector operations.
- Embedding recent travel/tourism data for similarity search: In the back end, you can use APIs and a web scraper to collect recent travel and tourism data and, using GPT, turn them into embeddings. Your app can then save these embeddings into a vector database and the relative metadata in Fauna.
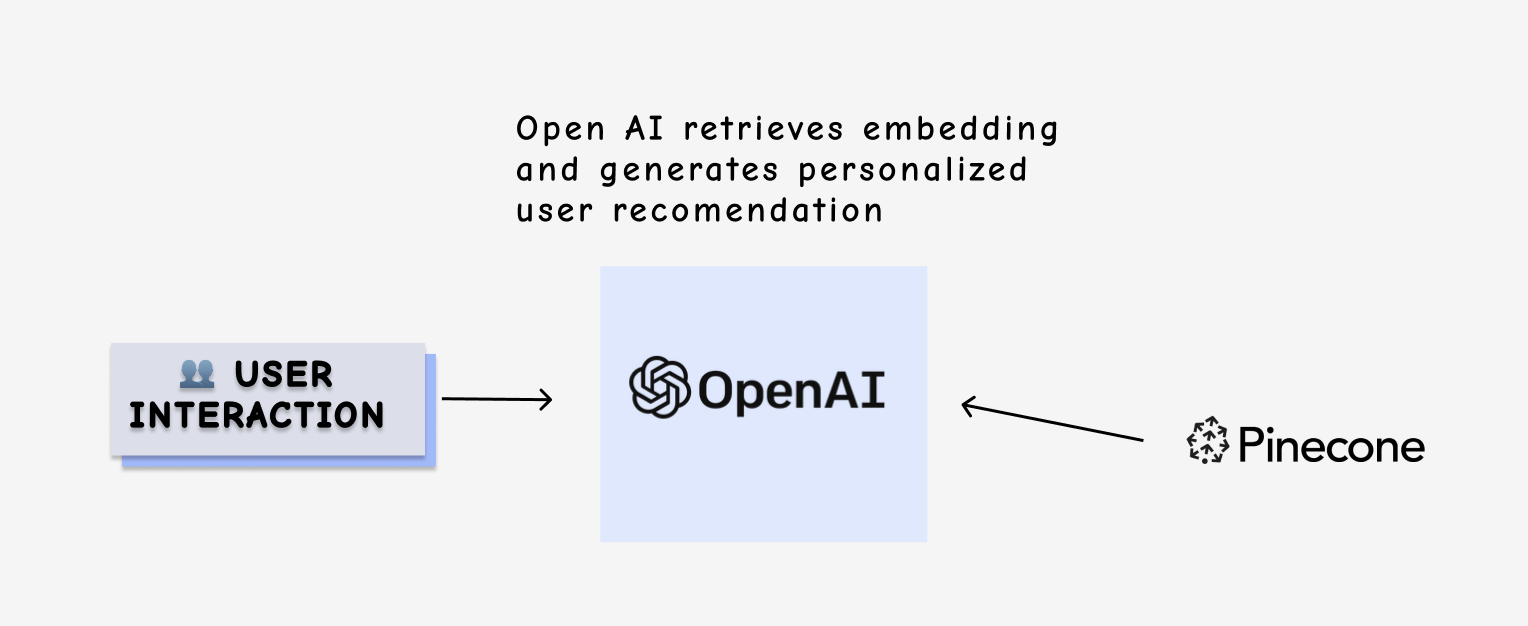
- Generating personalized recommendations: When the user asks for travel recommendations, the GPT agent queries both databases. The GPT agent combines the results from both databases, weighting the importance of each data point to generate a personalized list of travel recommendations. The agent then presents these recommendations to the user in a natural language format, explaining why each destination is a good fit based on the user's preferences and past experiences.
Sample application walk-though
Setting up the project
To build our demo application, we will use langchain. It is a framework for developing applications with large language models. You can find the complete code in this Google Colab and the sample data here.
Install the required libraries by running the following command.
pip install langchain
pip install faunaConfigure a Fauna database
Head over to dashboard.fauna.com and create a new database.
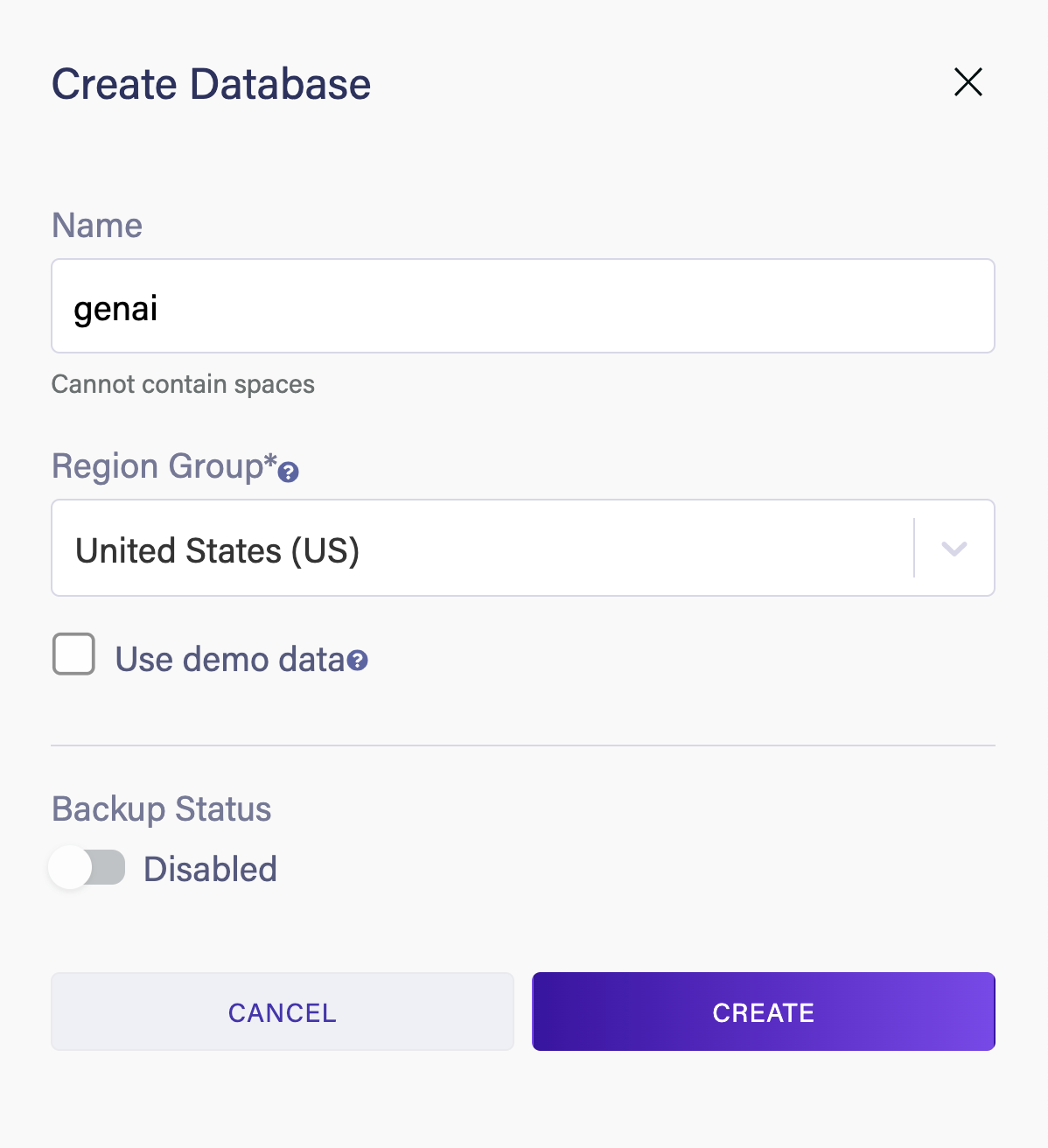
Once you create a new database create two new collections called
User and Place.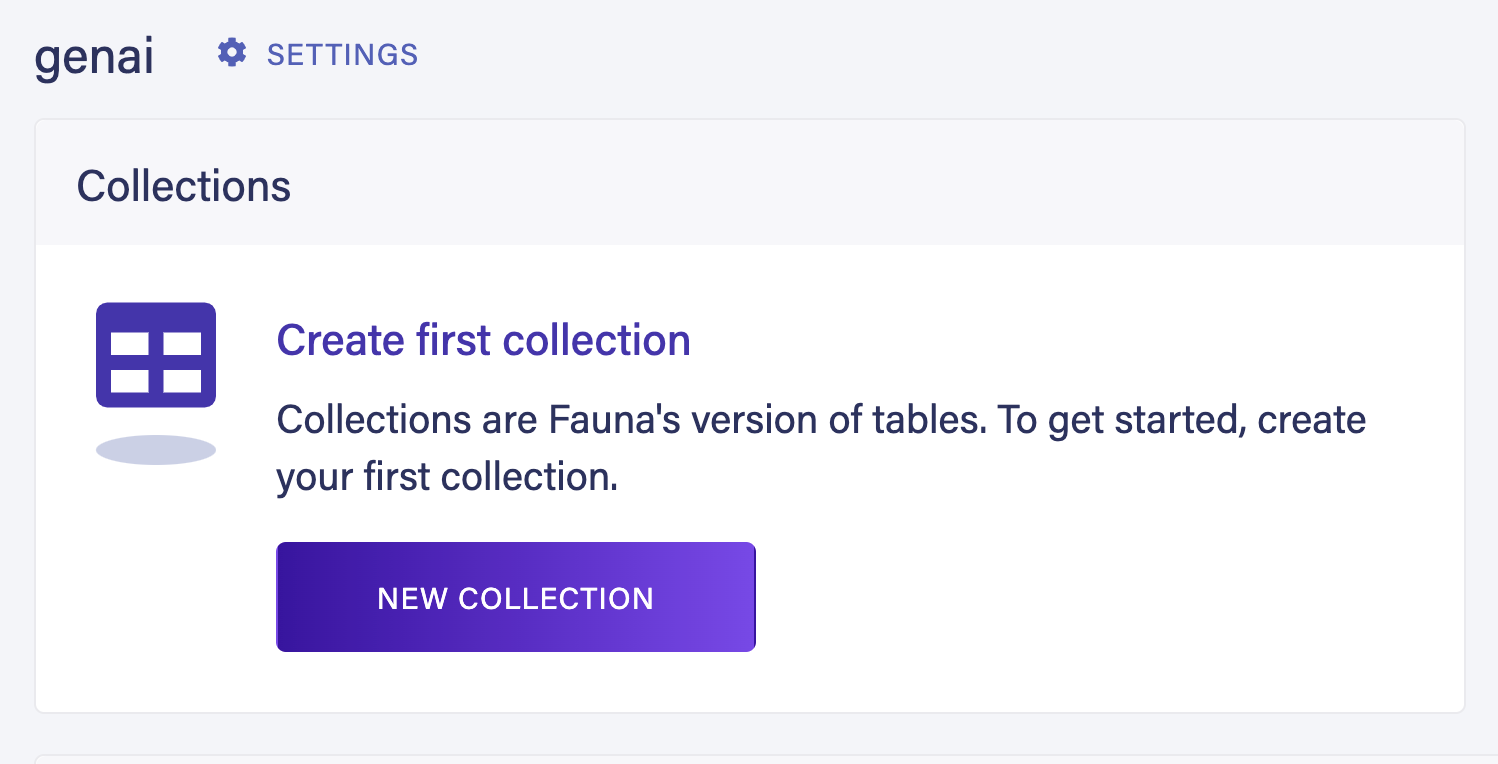
Next, go to the Security section and create a new server key to connect to the database from your code.
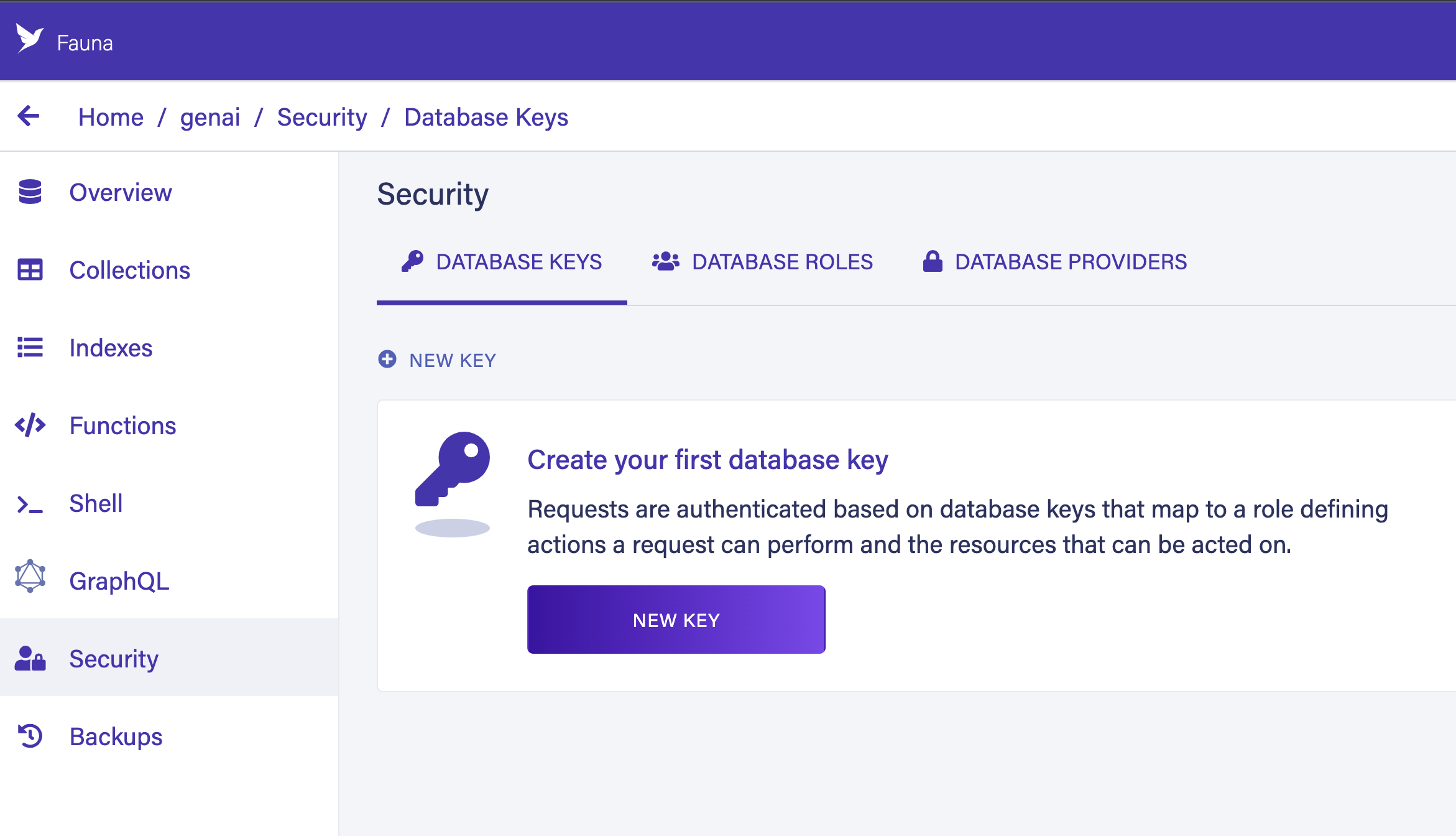
Secure the newly generated key.
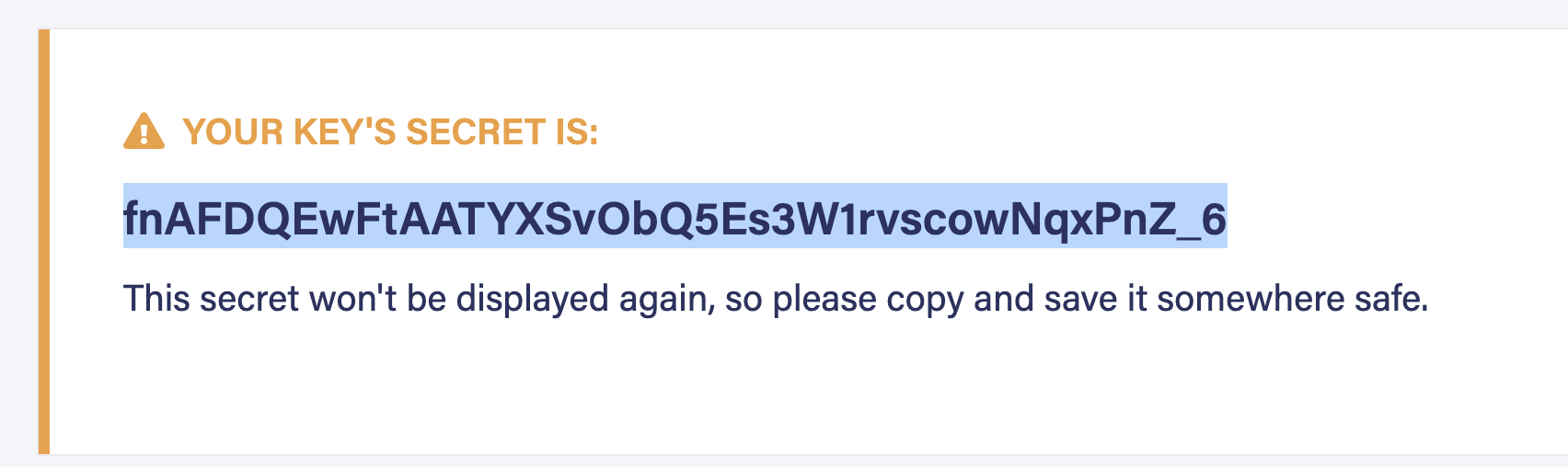
Seeding the data
Since we are not building any UI component for this demo app, we will imagine that the user has already registered for the application. When a new user is registered a new record is created in the
User collection in Fauna database. Run the following code to create a user.
from fauna import fql
from fauna.client import Client
from fauna.encoding import QuerySuccess
from fauna.errors import FaunaException
import os
os.environ['FAUNA_SECRET'] = 'fnAFDQEwFtAATYXSvObQ5Es3W1rvscowNqxPnZ_6'
client = Client()
q1 = fql("""
User.create({
name: "Shadid",
age: 29
})
""")Next, we will seed the Fauna database with records of places to visit. A CSV file is provided here with a list of tourist attractions in US. Let’s seed the database with these data. Run the following code to read the CSV and insert them to
Place collection in Fauna.import csv
csv_file_path = "places.csv"
with open(csv_file_path, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
query = fql("Place.create(${x})", x=row)
res: QuerySuccess = client.query(query)Now we have all the generic information saved in our general purpose database. Next, we want to convert each place’s activities into vector embeddings. Later, we can match user preference to these embeddings.
To store the vectors we’ll use Pinecone. Head over to Pinecone and create a new index. Call your index
places.Run the following code to generate vector embeddings and insert them into Pinecone.
import openai
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
os.environ['OPENAI_API_KEY'] = '<Your-Open-AI-Key>'
pinecone.init(api_key="<Your-Pinecone-Key>", environment="northamerica-northeast1-gcp")
openai.api_key = os.environ['OPENAI_API_KEY']
index = pinecone.Index("places")
output = []
with open('places.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for i, row in enumerate(reader):
activities = row['activities']
generate_embeddings = openai.Embedding.create(input=activities, model="text-embedding-ada-002")
emb = generate_embeddings['data'][0]['embedding']
output.append((str(i) + "", emb, { 'state': row['state'], 'name': row['name'] }))
# output
index.upsert(output)Using langchain's prompt templates, we can initiate our chat agent and gather data about user travel preferences.
from langchain import PromptTemplate
template = """
Act as a travel agent and find the user's travel preference from following user input
{context}
"""
prompt = PromptTemplate(
input_variables=["context"],
template=template,
)
prompt.format(context="<conversation-chain...>")As the conversation progresses, we will keep collecting helpful information about the user. Let's imagine the user gives the following information about his/her travel preference.
I like the outdoors. I am looking for a place where there is chances to see wildlife, lots of hiking and I can ride my bikeBased on this information now we can perform a similarity search in the vector database. The following code snippet demonstrates this.
query = "I like the outdoors. I am looking for a place where there is chances to see wildlife, lots of hiking and I can ride my bike"
xq = openai.Embedding.create(input=query, model="text-embedding-ada-002")['data'][0]['embedding']
res = index.query([xq], top_k=5, include_metadata=True)
res['matches']*Note: We are using the new text-embedding-ada-002 model from OpenAI here. This replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.*
This will return places with similar activities. Next, we can query the Fauna database again to get specific details about these places and using langchain generate a final response to the user. The following code demonstrates this.
from langchain.chains import LLMChain
from langchain.llms import OpenAI
places = res['matches']
places = places[::-1]
places
results = []
for place in places:
query = fql("Place.where(.name == ${x}) { name, description }", x=place['metadata']['name'])
item = client.query(query)
doc = item.data
results.append(doc.data[0])
resultsllm = OpenAI(temperature=0.9)
print(llm(result))In conclusion, the integration of a general purpose database, such as Fauna, and a vector database like Pinecone with GPT agents has the potential to revolutionize the user experience in applications like WanderWise. This synergy enables the development of AI-powered services with long-term memory capabilities, resulting in more relevant, personalized, and context-aware interactions.
We only scratched the surface of what is possible. To learn more join Fauna’s Discord channel or visit one of our workshops. For more details see our post on why Fauna is an ideal fit for the transactional database requirements dictated by a typical gen AI application.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.