

Fauna: A modern system of record for your generative AI application
What you'll read
Why to include Fauna in your generative AI stack
In order to build a scalable and performant application, a modern operational database is needed to serve as the system of record.
➡️ Introduction to generative AI apps
➡️ Generative AI app architectures
➡️ Databases used in generative AI apps
➡️ Operational database requirements for generative AI apps and why Fauna
Introduction to generative AI apps
Generative AI has quickly emerged as a disruptive force across a wide range of industries. These systems use deep learning algorithms to model the probability distribution of the training data and generate new samples from it. As a result, a new paradigm of applications and architectures are emerging on top of these novel capabilities.
This blog will introduce the foundational elements of a generative AI app to help surface typical database requirements, and illustrate why those requirements lead to Fauna being adopted as the AI system of record in the generative AI stack responsible for storing and relating metadata, context, user data, and general application data alongside a vector database. Fauna’s value extends beyond the table stakes features expected of a transactional database in the context of generative AI apps; its relational power in the context of a document data model, API delivery model, and expressive and powerful query language enable it to serve as a transactional engine that drives additional value to a generative AI app and ultimately deliver a superior end user experience.
Generative AI architectures
The broad contours of a generative AI stack can be categorized by three layers:
- Application: The topmost layer in the system architecture that interacts with users or external systems and serves as the connective tissue between the generative AI models and the application itself (API tooling, serverless functions, orchestration tooling, etc.). The application layer enables interaction, processes requests and outputs, and ensures a seamless and secure experience for users and external systems.
- AI model: The generative models, their training, fine-tuning, and management, as well as input and output processing. It is the core component responsible for generating novel content based on the input data and user-defined parameters.
- Infrastructure: The core hardware (i.e. GPU’s offered by firms like Nvidia), the cloud compute and hosting functions (hyperscale infrastructure providers like AWS, Azure, and GCP), and other infrastructure primitives (i.e. databases).
We will focus on the database component of the infrastructure layer, as generative AI apps rely on both a modern transactional database like Fauna to serve as the system of record, as well as an additional database type compared to a standard modern application: vector databases.
Databases used in generative AI apps
A modern operational database like Fauna, combined with a purpose built vector database, can provide developers with a powerful set of tools for building generative AI apps.
Fauna is used as the transactional engine for storing general application and user data, metadata, context and conversation history, as well as to filter or aggregate data in specific ways to get the desired output.
Vector databases have been purpose-built to store vector embeddings, used to retain and manipulate high-dimensional image, audio, and text vector embeddings. Today's vector databases are laser-focused on providing effective similarity search, which is a critical capability for AI-driven applications. A vector representation can be used in a variety of applications including natural language processing, image recognition, and recommendation systems.
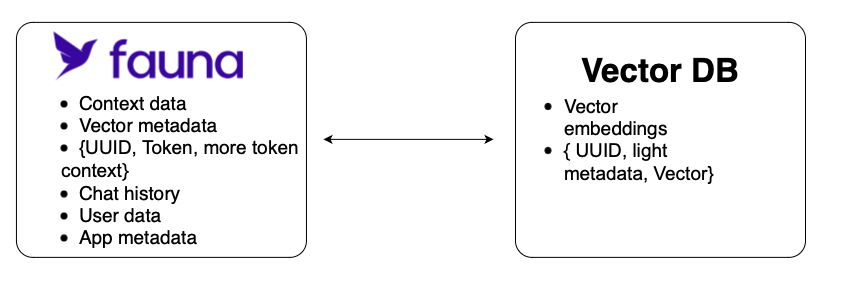
Fauna: The operational database for generative AI apps
Using a general purpose database and metadata store like Fauna alongside a vector database has proven to be a powerful combination for building generative AI apps. The majority of generative AI apps are built with modern architectural components such as APIs and serverless functions, and ultimately benefit from a modern operational database that can efficiently integrate with vector databases and other components of the generative AI stack, while accommodating the unique attributes of a typical generative AI app. Gen AI apps produce disparate forms of data at high volumes, including application data, metadata user data, vector embeddings, conversation history, and other forms. Fauna’s ability to support relations within the context of documents helps builders that need a system of record that can accommodate these diverse data types without sacrificing relations.
The following represent some of the specific database requirements of a generative AI app, and how Fauna is uniquely positioned to satisfy these requirements:
Context storage
When a user prompts an LLM, it creates a historical record in the underlying database (e.g. the conversation history up to a certain point in a chatbot). Storing context data is essential for enabling the AI model to generate relevant and coherent outputs based on the user's inputs and previous interactions. Context data includes any information that could be relevant to the current conversation or task at hand, such as the user's preferences, history of previous interactions, and any relevant environmental or situational factors.
For example, consider a chatbot that helps customers book travel arrangements. If the chatbot doesn't have access to any previous conversation history or contextual information about the user, it might struggle to provide helpful responses to the user's requests. However, if the chatbot has access to the user's previous booking history, preferred airlines, and travel dates, it can generate more relevant and helpful responses based on that context.
Why Fauna: Data model flexibility and power
Context is typically unstructured and more naturally stored in documents, compared to the tabular structure of a relational database. Fauna’s document-relational data model supports both structured and semi-structured data and stores data in documents while allowing developers to apply relations to that data, which can accommodate the diverse data types and structures required by generative AI apps. Further, the Fauna Query Language (FQL) is a powerful and expressive language that enables complex queries and operations against this context data - so developers aren’t cornered into workarounds to accommodate relationships between pieces of relevant data.
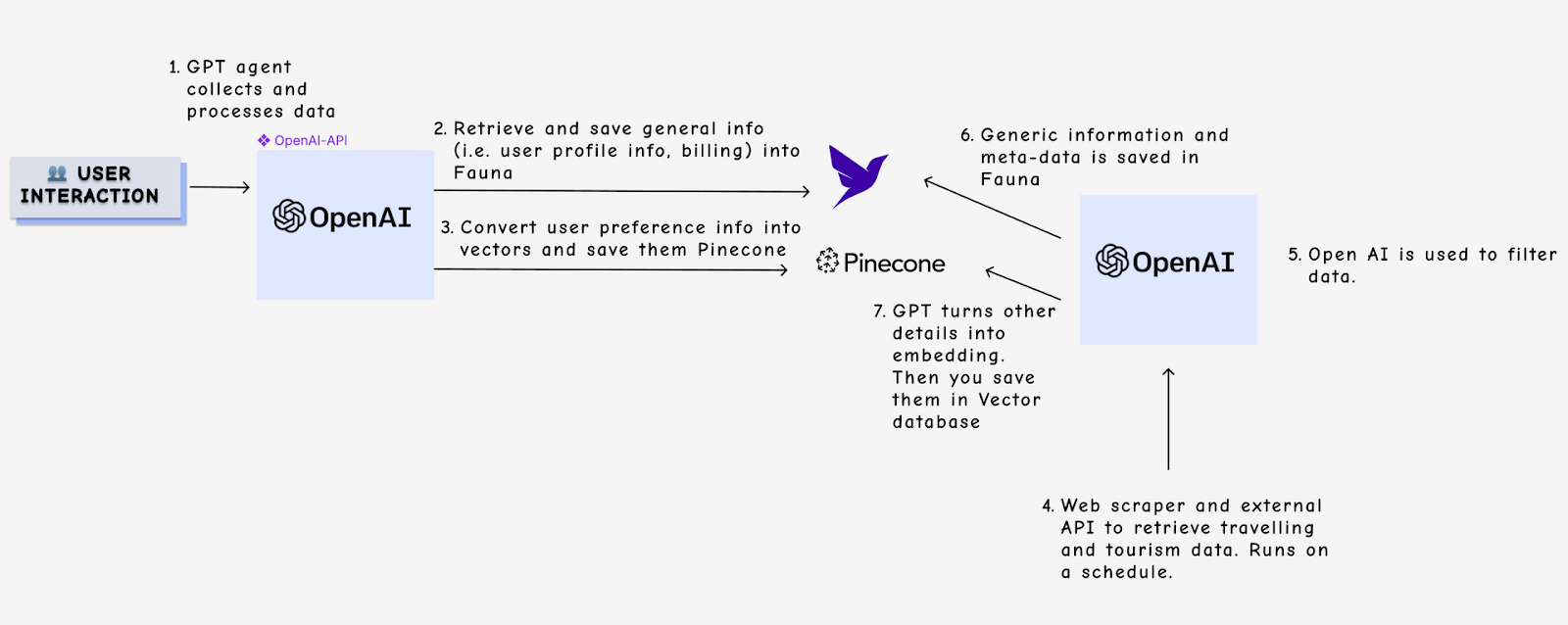
Example architecture from a Fauna generative AI travel booking sample application built with OpenAI and vector database Pinecone
Metadata storage
Metadata storage also plays a crucial role in a generative AI app as it acts as a repository for all the relevant metadata associated with the data used by the model. This metadata is often unstructured and includes information such as the data's source, format, structure, provenance, and lineage. It can also include any additional information that can help in managing the data and the model, such as training parameters, model configurations, and performance metrics.
Why Fauna: Scalability and compatibility with vector databases
Unlike other document databases, developers building generative AI apps on Fauna can accommodate unstructured metadata without sacrificing the ability to traverse relationships between critical entities within an application via joins, filters, or foreign keys. This flexibility simplifies the process of storing, querying, and managing various types of data, such as raw data, metadata, context data (e.g. chatbot conversation history), or model configurations. This also extends to storing and querying embeddings metadata (sessions, mappings, and metadata corresponding to embeddings), and managing relations between the embedding metadata.
Knowledge graph
A knowledge graph is used in a generative AI app to organize and represent information as interconnected concepts and entities, where each piece of data is represented as a node in the graph and linked to other related nodes. The nodes in a knowledge graph typically contain information such as names, attributes, relationships, and properties, and they can be enriched with additional data from various sources. Generative AI models can leverage this information to produce more coherent and accurate responses to queries or generate more contextually relevant outputs.
Why Fauna: Relations applied on documents with fine-grained access control
While graphs can be modeled in tabular form, they are again more naturally structured as documents and benefit from Fauna’s relational capabilities. With native Fauna features like ABAC (attribute-based access control), Fauna can be leveraged to manage access to the vector data, ensuring that only authorized users can access or modify the data - which is particularly powerful compared to legacy databases where this fine-grained access control isn’t achievable. Meanwhile, introducing child databases to an application built on Fauna is easy and intuitive - enabling builders to isolate storage for knowledge graph or metadata.
Composability + integrations
Integrating the generative AI app with other systems or platforms, such as databases, compute functions, user interfaces, or external APIs, can become more complex as the scale of the application grows. Taking an API-first approach at the operational database layer helps reduce the reliance on brittle integration code or connection pooling and offers a superior user experience.
Why Fauna: API delivery model and composability with modern tooling
Fauna is accessed via an API, which allows it to seamlessly integrate with different pieces of the application including ephemeral compute functions delivered via HTTP. This reduces the total cost of ownership by eliminating connection pools needed to maintain TCP/IP connections, as well as the engineering time dedicated to maintaining integration code. Fauna's serverless model automatically scales based on demand, ensuring that the generative AI app can handle varying workloads without manual intervention - enabling application developers to focus on optimizing their application instead of backend infrastructure.
Case study: Logoi
Let’s take it out of the abstract and into a real-world customer example to better understand some of the design decisions generative AI app builders are taking.
About Logoi
Enterprises are leaky sieves of knowledge; not because people can't find the right documents and resources, but because they are missing context. Logoi knows what search is missing. Most of that knowledge is being shared ad hoc through Slack, Zoom, or word of mouth - if it's being shared at all. This requires employees to ‘know the right people’ to gain access - an extra challenge for newly on-boarded employees. And when those key knowledge holders leave, they'll still walk away with about 50% of that contextual knowledge locked in their heads. Logoi addresses this problem by plugging into your company's communication channels and determining what knowledge is being shared where, so when someone asks a question, Logoi can match them to the right person or information, automatically, with no time wasted searching for answers or reinventing the wheel. Logoi catalogs the tacit knowledge that search is missing, making it your company's most valuable employee.
Logoi architecture
Semantic search is a powerful way to make large amounts of data searchable, but that power comes at the cost of always losing some signal. For Logoi's problem, de-noising conversations in order to get at the knowledge communicated along the way, semantic search and data stored in vector databases provide the searchable space but the words themselves don't provide all the answers.
Central to Logoi’s philosophy is that knowledge is more than just data. To know how people are transferring knowledge (or not), Logoi needs to know about people, their interactions, what they've said explicitly and also what might be implied or missing. Logoi returns both specific knowledge and generalized or larger scale knowledge and insights, including time-bound knowledge and knowledge that may change in significance over time.
“Using Fauna as our metadata store allows us to record and update layers of knowledge in ways that are each appropriate to the varied types of knowledge we will need to access,” shared Allen Romano, Co-Founder at Logoi. “Using Fauna as a document database, we can access a source of truth about the conversation itself. It's very important to us that Fauna is a document database, but we can still apply relations. Then leveraging Fauna as a knowledge graph we can access information about people, knowledge, documents, and their interrelationships. Finally, Fauna plus a vector database allows us to output and surface information both from each database itself and from accessing one by means of the other. For example, using the results of vector search to then trace deeper relationships that we have separately parsed and stored as part of the knowledge and social graph in Fauna, encoded as granular edges and nodes in the knowledge graph, indexed text, and compressed into word embeddings.”
If you're interested in learning more about Logoi and how they might be able to support your business, schedule a demo.
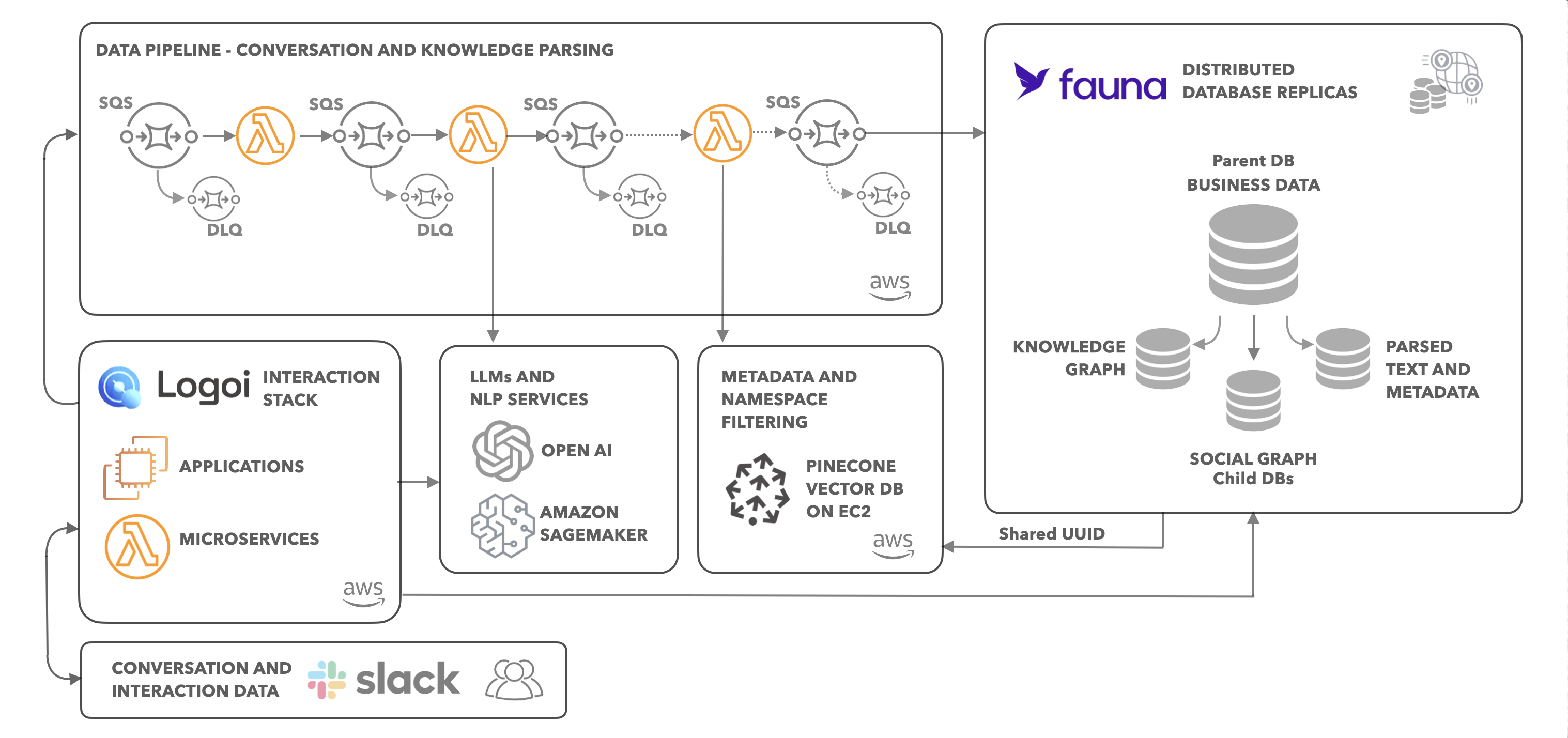
Fauna as the gen AI system of record
Gen AI apps require some novel elements to deliver critical AI functionality; however, much of the broader architecture resembles how a more standard modern application is built and delivered today. In order to build a scalable and performant application, a modern operational database is needed to serve as the system of record. Fauna is a particularly powerful choice for these architectures due to its API delivery model, flexible data model, and powerful and expressive querying language, offering gen AI app builders both the structure and power to help scale their application and adapt to changing access patterns over time.
Do you have a requirement for a system of record in your application and looking for a scalable, secure, and API-first database? Don’t take our word for it, check out this sample app and tutorial illustrating a gen AI app built on Fauna, start building, and see for yourself.
Get in touch with one of our experts today if you have any questions.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.